
https://kyeum-d.tistory.com/31
[Object Storage] 객체 저장소, 왜 선택되었나 ?
들어가며... 사이드 프로젝트로 강의 플랫폼 프로젝트를 진행하면서 가장 핵심이 되는 강의 파일 업로드에 대한 처리를 어떻게 해야할지 고민했습니다. 이번 포스팅에서는 대표적인 Storage별 장/
kyeum-d.tistory.com
(지난글)
들어가며...
지난 글에서 Object Storage를 선택한 근거와 특성에 대해서 알아봤습니다.
이번글에서는 실제로 강의 프로젝트에서 강의를 업로드 하기 전 기본적인 Object Storage 동작을 익혀보겠습니다.
사용된 API는 AWS의 Simple Storage Service - S3 입니다.
Bucket 생성
AWS console에서 버킷을 생성합니다.

ACL를 비활성화해서 모든 객체는 제 계정이 소유하도록 하고

추후 허용된 사용자에게 Key를 부여하여 해당 사용자만 버킷에 접근할 수 있도록 하기 위해 퍼블릭 액세스도 차단합니다.

현재로써는 버전을 관리할 필요는 없기 때문에 버전은 비활성화 합니다.

암호도 기본 암호화를 선택해주고 버킷을 생성합니다.

생성된 버킷을 확인할 수 있습니다.
Object(객체)를 업로드하자
최우선적이고 궁극적인 목표입니다. Bucket에 Object를 업로드 해야합니다.
Bucket에 Object를 Upload하는 방법은 크게 4가지가 있습니다.
- S3 콘솔을 사용(AWS website 에서 직접 업로드)
- AWS SDK 사용
- REST API 사용
- AWS CLI(Command Line Interface) 사용
강의를 업로드하는 것은 사용자의 역할이기 때문에 직접 업로드 행위를 해야하는 1번과 4번은 적절하지 않다고 판단했습니다.
따라서 SDK와 REST API를 사용하는 방법을 알아볼텐데 우선 SDK를 사용하는 방법부터 알아보겠습니다.
SDK를 통한 JAVA에서 객체 업로드
build.gradle에 해당 sdk를 import 합니다.
implementation(platform("software.amazon.awssdk:bom:2.20.56"))
implementation("software.amazon.awssdk:s3")
implementation("software.amazon.awssdk:sso")
implementation("software.amazon.awssdk:ssooidc")
bucket에 대한 정보와 object에 대한 정보를 작성합니다.

버킷의 이름, 객체Key, 객체Path를 작성합니다.
- bucketName : 객체를 업로드 할 버킷 이름
- objectKey : 업로드 할 객체의 Key(버킷에 올라가는 Key)
- objectPath : 업로드 할 객체가 현재 OS에서 위치한 경로
그런데 여기서 제가 처음에 당황했던 부분이 bucket 이름만 설정해주고 따로 bucket에 대한 정보를 추가하지 않는다는 점이였습니다. (분명 길고 장황한 코드로 된 bucket에 대한 식별 값이 어디 있을텐데)
왜 그런지 잘 살펴보니 S3의 Bucekt Name은 전세계에서 고유한 값이기 때문이였습니다.
일반적으로 Name이라고 하면 사용자 정의하기 나름인 값이라고 생각하여 전세계적으로 고유한 값이라는 생각이 잘 안들어서 당황했던 것 같습니다. 아싸 Infrun 먹었다
또 Object Key를 살펴보면 json\\SAN+V+75 ... 와 같은 계층구조를 나타내는 값이 존재합니다.
이전에 Object Storage는 분명 계층구조가 아닌 평면구조라고 했는데 어떻게 된 것일까요?
Object Storage에서도 이러한 계층 구조인 폴더를 지원합니다.
다만, Object Storage에서 제공하는 폴더는 File Storage의 폴더처럼 실제 물리적인 구조가 아닌 논리적인 구조입니다.
즉, Object key에 저렇게 전체 구조가 들어가는 것이고 해당 계층을 시각적으로 보기 편하게 하기 위해 구분하는 형태인 것입니다.
평면적인 구조지만 File Storage의 UI가 갖는 장점을 살린 부분이라고 볼 수 있습니다.
Region에 대한 정보를 작성합니다.

S3에 접속 할 Client를 생성해야 합니다.

여기서 많이 헤맨 부분이 있는데 바로 credentialProvider를 생성하는 부분입니다.
credentialProvider는 설정한 권한을 공급해주는 역할을 하는데
Infrun 버킷의 퍼블릭 액세스를 모두 막아놓았기 때문에 Infrun 버킷에 접속하기 위해서는 접근에 대한 권한을 부여받아야 할 것입니다.
그러기 위해서는 IAM(Identity and Access Management)에서 S3 Stroage에 대한 접근을 허용한 사용자를 추가해야 합니다.

그룹에 따라, 사용자에 따라, 정책에 따라 bucket 별 권한을 주는 것 이외에도 많은 디테일한 권한 부여가 가능하지만
당장 저희가 필요한 부분은 아니기에 S3에 대한 Full Access를 활성화 한 Profile을 하나 만들고 액세스 키를 발급 받습니다.
SDK에서 업로드 할 Profile을 생성하기 위해서는 AccessKey와 SecretKey가 필요합니다.
이 두가지 Key를 설정하기 위해서는 다음과 같은 방법이 존재합니다.
- Java 코드 내부에서 직접 선언
- Java 시스템 속성
- 환경 변수
- credential 파일
가장 먼저 Java 코드 내부에서 직접 선언하는 방법으로 작성해보겠습니다.

위와 같이 AwsBasicCredentials 클래스를 통해 credential 정보를 create하고 S3Client를 build 하는 과정에서
StaticCredentialsProvider를 통해 credential 정보를 제공합니다.
가장 간편하고 쉬운 방법이지만 코드에서 직접 accessKey와 secretKey를 관리하는 방식은 보안에 굉장히 취약한 방법입니다. 현재는 공유된 저장소에 해당 코드를 올리고 있고 이런 accessKey와 secretKey가 공유되는 것은 아주 위험합니다. 익명의 누군가가 이런 Key를 가지고 무단으로 bucket에 접근하여 객체를 휘집어 놓을 수 있기 때문이죠
따라서 코드에 직접 관리하는 방법보다는 따로 관리해주는 형태가 좋습니다.
저는 credential 파일을 따로 작성하여 해당 파일에 Profile Key에 대한 정보를 관리하겠습니다.
credential 파일로 Key를 관리하기 위해서는 직접 credential 정보를 생성하는 AwsBasicCredentials가 아닌
설정된 Key를 읽어올 클래스의 도움이 필요한데 ProfileCredentialsProvider 클래스가 이 역할을 해줍니다.
ProfileCredentialsProvider는 create 할 때 ProfileFile 클래스를 통해 credential 파일을 읽어옵니다.
이 때, 기본으로 설정된 경로는 Home Directory의 /.aws/credentials 입니다. 여기서 처음에 credentials 폴더를
만들어야 하는줄 알고 헤맸으나, 결론적으로 home/.aws/ 폴더에 credentials 파일을 만들어야 했습니다.
credentials 파일을 생성하고 정보를 입력하여 저장합니다.

그런데 여기서 문제가 발생합니다.

해당 Profile에 어떠한 credentials 정보도 포함되어 있지 않다는 내용의 Client Exception이 발생합니다.
파일이 제대로 읽히지 않은 것 같습니다. 경로가 이상하거나 파일을 잘못 작성했다는 의미일 것입니다.
공식문서를 확인했으나 경로와 파일작성에는 문제가 없었습니다.
그렇다면 남은 것은 실제 코드에서 어떤 파일을 읽어들이는지 확인하는 방법 뿐입니다.
디버깅을 통해 ProfileFile의 FileLocation 설정을 확인합니다.
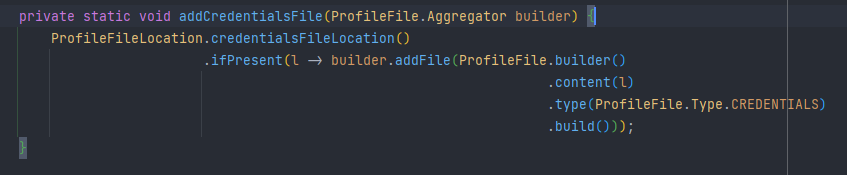
ProfileFileLocation 클래스에서 설정하는 것을 확인 할 수 있습니다.

userHomeDirectory의 .aws에 credentials 경로인 것을 확인 할 수 있습니다.

실제로 출력해보니 해당 경로가 나왔습니다.
그렇습니다. 제가 credentials.txt로 만들어놔서 해당 정보가 읽히지 않았습니다..😅
우여곡절 끝에 credentials 파일을 생성하여 Object를 전송합니다.

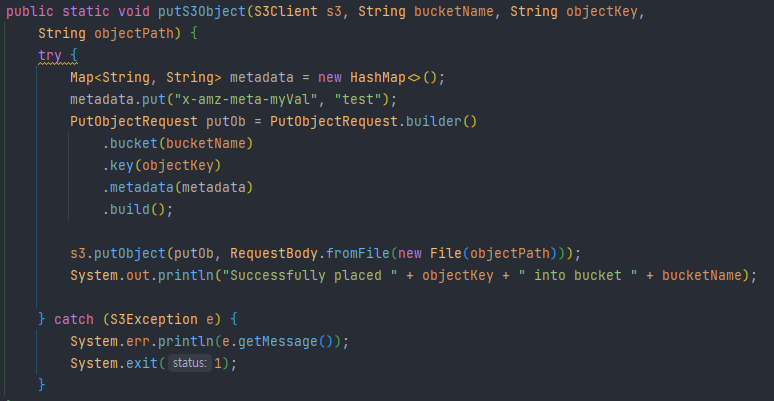
이전 글에서 Object Storage는 metadata를 포함하여 저장 할 수 있다고 했는데 실제로 위와 같은 방법으로 metadata를 함께 저장 할 수 있습니다.
실행하면

성공적으로 bucket에 객체를 올렸다는 메세지가 발행됩니다.
실제 console에 가서 확인해보겠습니다.


메타데이터를 포함한 객체가 정상적으로 업로드 된 것을 확인 할 수 있습니다.
고려사항
그런데 여기서 SDK를 통한 객체 업로드를 하기 위해서는 서버에 파일이 저장되어 있어야 합니다.
강의를 업로드 하는 것은 유저의 행위입니다. Front-end 에서 브라우저를 통해 유저는 강의를 업로드 할 것입니다.
그 때 SDK를 통한 객체 업로드를 활용한다면 Front에서 전송한 영상 데이터를 Infrun 서버에 저장하고 저장된 영상 데이터를 다시 Object Storage로 업로드 하는 과정이 필요합니다.
여기서 불필요한 네트워크 전송이 발생합니다. 이러한 작업은 용량이 크지 않은 파일을 다룰 때는 문제가 없지만 영상 같은 크기가 큰 데이터를 다룰 때는 굉장히 부담스러운 작업입니다.
더군다나 불안정한 네트워크에서 언제 영상의 업로드가 끊길지 불안한 상황에서 두번이나 위험을 감수한다는 것은 더욱 힘든 일입니다.
따라서 저희는 최종적으로 REST API를 통한 업로드를 구현해야합니다.
다만 REST API를 통해 영상 데이터를 업로드 할 때도 고려해야 하는 사항이 크게 두가지가 있습니다.
- 용량이 큰 영상을 업로드 할 때 네트워크 장애로 인한 처리를 어떻게 할 것인가
- 어떻게 영상이 업로드 되는 것과 강의에 대한 정보가 업로드 되는 것을 하나의 트랜잭션으로 묶어서 관리할 것인가
다음 포스팅에서는 REST API를 통한 객체 업로드를 진행해보고
어떤 방법으로 트랜잭션을 구현할 것인지, 네트워크 장애에 어떻게 대응 할 수 있는지, 용량이 큰 영상 데이터를 어떻게 효율적으로 업로드 할 것인지에 대해 다뤄보겠습니다.
다음글
https://kyeum-d.tistory.com/33
[Object Storage] - REST API를 통한 S3 Multipart Upload
들어가며 지난 시간에 Java SDK를 활용해 Object Storage에 객체를 업로드 해봤습니다. 그런데 여기서 SDK만을 활용하여 업로드하면 어떻게 될까요? 총 2가지의 문제가 발생합니다. 클라이언트에서 전
kyeum-d.tistory.com
예제코드
https://github.com/kyeumd/aws_s3_multipart_upload
GitHub - kyeumd/aws_s3_multipart_upload
Contribute to kyeumd/aws_s3_multipart_upload development by creating an account on GitHub.
github.com
'Data' 카테고리의 다른 글
| [Object Storage] - REST API를 통한 S3 Multipart Upload (1) | 2023.09.03 |
|---|---|
| [Object Storage] - 객체 저장소, 왜 선택되었나 ? (0) | 2023.08.20 |
| [전문검색] - 형태소 분석의 이해 (0) | 2023.08.13 |
| [전문검색] - Like 검색 vs 전문검색(n-gram) (0) | 2023.07.23 |