
들어가기에 앞서...
교육강의 플랫폼 infrun의 강의 검색 기능을 개발하던 중 강의명에 대한 검색을 Like절을 사용하여 처리하였고
이러한 질문을 받았습니다.
Like 검색을 사용 했을 때 DB에서 어떤 일이 발생할까요?
막연히 앞뒤로 %가 붙은 like 검색은 인덱스를 타지 않고 느린 검색이다 라고만 알고 있었는데
원론적인 질문에 쉽게 답을 할 수 없었고 실제로 어떤 차이가 있는지 궁금해졌습니다.
그래서 오늘은 RealMySQL 8.0 에서 읽은 내용을 기반으로 Like 검색의 문제점과 문제점을 해결하기 위한 전문검색의 차이를 알아보는 시간을 가져보겠습니다.
테스트 해 볼 상황
- Like 검색 (%~%)
- 전문 검색(n-gram 알고리즘)
* 테스트 데이터는 공공데이터 포털의 코로나 뉴스 집합 데이터를 사용했습니다.
https://www.data.go.kr/
1. 아무런 인덱스 없이 Like 검색

총 5만건의 데이터로 테스트를 진행합니다.
SELECT *
FROM covid_full_text
WHERE contents LIKE '%자원봉사대%';먼저 쿼리의 실행계획을 살펴보겠습니다.

Using where 로 처리되는 모습
like 검색을 실행합니다.
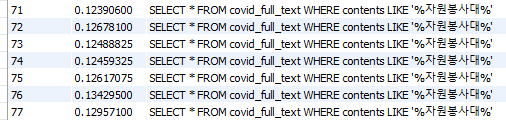
실행까지 평균 0.125sec 가 걸리는 것으로 확인됩니다.
prefix가 아닌(LIKE "~%" 형태) 쿼리는 인덱스를 생성한다고 하더라도 인덱스를 활용 할 수 없습니다.
🧐 Like검색에서 Optimizer는 왜 index를 사용하지 않을까?
- MySQL InnoDB로 생성하는 Index_type을 보면 기본적으로 BTREE 라고 적힌 것을 확인 할 수 있다.
- B-Tree(Balanced-Tree, ※Binary 아님 주의)는 key가 되는 값으로 정렬을 하여 루트/브랜치/리프 노드로 구성된 구조임
👉🏼 따라서 Like 검색어의 %~% 를 사용하게 되면 index의 범위 탐색이 불가능하여 index를 의미있게 사용하기 어려움(커버링 인덱스의 경우는 유의미 할 수 있음)
※ prefix만 사용한 검색은 index 사용 가능
2. 전문 검색(n-gram 알고리즘)
전문 검색은 문서의 키워드를 인덱싱 하는 방법에 따라 크게 2가지로 구분 할 수 있습니다.
- 어근 분석 알고리즘
- n-gram 분석 알고리즘
어근 분석은 단어 사전을 기반으로 문장의 구조를 인식하여 의미를 가지는 단어를 선정하는 전문적인 알고리즘이여서 범용적으로 사용하기 어렵고
완성도 있는 검색을 제공하기 위해서는 많은 시간과 노력이 필요한 방법이므로 다음 포스팅에서 자세하게 알아보도록 하겠습니다.
그러한 이유로 이번 글에서는 2번 방법인 n-gram 분석 알고리즘을 활용한 전문 검색 방법으로 테스트를 진행합니다.
🧐 n-gram 분석 알고리즘이 뭔데?
본문을 n개의 글자로 잘라서 인덱싱 하는 방법이다.
생성되는 인덱스 크기가 상당히 큰 편이지만 단순하고 국가별 언어에 대한 이해와 준비 작업이 필요 없다는 장점이 있다.
일반적으로는 2글자 단위로 잘라서 사용하는 bi-gram 알고리즘을 방식이 많이 사용됩니다.
ex) "apple" 👉🏼 "ap" "pp" "pl" "le"
(n-gram 분석 알고리즘에 대한 자세한 동작 방식이 궁금하신 분은 추가자료를 찾아보시는 것을 추천드립니다)
MySQL의 n-gram 전문검색
MySQL은 전문검색을 활용 할 인덱스를 생성할 때 "불용어"를 제외하고 등록하는 전처리 과정을 거칩니다.
따라서 n-gram 알고리즘을 활용해 인덱스를 생성하는 과정또한 불용어를 제외하고 등록됩니다.
🧐 불용어 ?
자체적인 의미를 가지지 않고 너무 빈번하게 등장하여 분석에 큰 도움이 되지 않는 용어
즉, 문맥을 이해하는 데 도움이 되지 않으며, 분석에 추가적인 부담을 주는 관사, 조사, 조동사 등을 의미함
영어에는 "the, a, an, is, and" 등이 해당하며
한국어에는 "이, 그, 있, 않, 아니, 그리고" 등이 해당합니다.
(일반적으로 정의하는 불용어 목록은 위와 같지만 시스템에서 정의하기 나름입니다.)
MySQL에서 정의한 불용어 목록은 INNODB_FT_DEFAULT_STOPWORD에서 확인할 수 있습니다.
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD;
여기서 주의해야 할 점은 a 같은 한글자 단어 또한 포함되어 있다는 것인데
이는 "Wakanda" 같은 단어를 bi-gram 인덱싱 하면 "Wa" "ak" "ka" "an" "nd" "da" 로 생성되고 "a"를 포함하는 모든 단어를 제외하고 "nd"만 인덱스로 최종 등록된다는 것을 의미합니다.
일반적으로 n-gram 알고리즘을 사용한 전문 검색에는 검색 품질 저하를 우려해 불용어를 잘 사용하지 않지만
(nd이외의 단어로는 Wakanda를 검색할 수 없는 상황처럼)
MySQL에서는 기본값으로 불용어를 사용하는 전략을 선택했습니다.

공식 archive 에는 CJK에서 불용어를 제거하기 위해 사용한다고 합니다 근데 왜 영어에...
오늘 해볼 테스트에서는 검색 품질 저하를 방지하고자 불용어를 사용하지 않는 전략을 선택하겠습니다.
(custom 불용어 테이블을 사용하는 방법도 있지만, MySQL에서 한국어의 default 불용어가 존재하지 않기 때문에 테스트 데이터도 한국어인 겸 한국어로 테스트를 진행하겠습니다)
contents 컬럼을 기준으로 FULLTEXT 인덱스를 생성합니다.
CREATE FULLTEXT INDEX full_contents ON COVID_FULL_TEXT (contents) WITH PARSER ngram;
생성된 인덱스를 확인해보면

Index_type이 FULLTEXT로 되어 있는 것을 확인 할 수 있습니다.
SELECT *
FROM covid_full_text
WHERE MATCH(contents) AGAINST ('자원봉사대' IN BOOLEAN MODE);문법 또한 LIKE가 아닌 MATH - AGAINST를 사용합니다. LIKE 역할을 IN BOOLEAN MODE가 대신해줍니다.

0.0023 sec의 속도로 일반 LIKE검색보다 50배정도 빠른 실행 속도를 보여줍니다.
🤔왜 이런 결과가 나올까?
우리는 n-gram 기법을 통해 전문검색 인덱스를 생성했습니다.
즉, 전문검색은 인덱스를 통한 찾기를 실행합니다.
전문검색 인덱스의 내부 구조는 이렇습니다.

- WORD : 생성된 인덱스 단어
- FIRST_DOC_ID : WORD가 처음으로 등장하는 DOC_ID
- LAST_DOC_ID : WORD가 마지막으로 등장하는 DOC_ID
- DOC_COUNT : INDEX에서 이 단어가 포함 된 행의 갯수
- DOC_ID : 이 단어가 있는 DOC_ID
- POSITION : DOC_ID 내에서 이 단어의 위치
(여기서 DOC_ID는 내부적으로 레코드의 행을 의미합니다)
SELECT *
FROM covid_full_text
WHERE MATCH(contents) AGAINST ('자원봉사대' IN BOOLEAN MODE);따라서 AGAINST 절의 ('자원봉사대' IN BOOLEAN MODE) 은
"자원"
"원봉"
"봉사"
"사대"
- 4가지의 단어의 인덱스를 전부 가지면서
- 각 WORD의 POSITION이 이어지는
레코드를 찾고 해당 레코드의 DOC_ID를 통해 실제 필요한 데이터에 접근하여 최종 결과를 반환합니다.
예시)
"모충동자원봉사대는" 이라는 문장을 bi-gram 알고리즘을 통해 인덱싱 하면
"모충" "충동" "동자" "자원" "원봉" "봉사" "사대" 총 6개의 인덱스가 생성되고
요구하는 4가지 단어의 인덱스를 전부 가지고 있고 이어진 POSITION을 갖기 때문에
검색 결과로 도출 될 수 있습니다..
이러한 작업을 통해 index를 사용하지 못하는 Like "%자원봉사대%"의 검색보다
실행속도가 훨씬 빠른 것을 확인 할 수 있습니다.
마치며
전문검색 인덱스가 내부적으로 생성되는 과정을 보면 이런 생각이 듭니다.
"인덱스 크기가 장난이 아니겠는데..?"
그렇습니다. n-gram 형태의 전문검색 인덱스의 큰 단점은
하나의 레코드에 대해서 수십, 수백개의 인덱스를 생성하기 때문에
생성되는 인덱스의 크기가 방대하다는 것입니다.
실제 제가 테스트 한 케이스의 경우 contents의 길이가 길다보니 5만건의 데이터를 인덱싱한 결과가 몇백만건이 나오는 상황이 생겼습니다.
다음 포스팅에서는 이러한 문제를 해결하기 위해 나온 형태소 분석, 역 인덱스, 에 대해서 다뤄볼까 합니다.
.
.
.
.
https://github.com/f-lab-edu/infrun
GitHub - f-lab-edu/infrun: 교육 강의 플랫폼
교육 강의 플랫폼. Contribute to f-lab-edu/infrun development by creating an account on GitHub.
github.com
(질문을 받은 사이드 프로젝트)
'Data' 카테고리의 다른 글
| [Object Storage] - REST API를 통한 S3 Multipart Upload (1) | 2023.09.03 |
|---|---|
| [Object Storage] - Java SDK를 활용한 S3 Upload (0) | 2023.08.26 |
| [Object Storage] - 객체 저장소, 왜 선택되었나 ? (0) | 2023.08.20 |
| [전문검색] - 형태소 분석의 이해 (0) | 2023.08.13 |